Robots.txt
The robots.txt file is a simple text file placed in the root directory of your website. It instructs web crawlers (also known as robots or bots) on how to crawl and index the pages on your site. By specifying which parts of your website should be crawled and which should not, you can control how search engines interact with your site.
Key Components of Robots.txt
- User-agent: Specifies the web crawler to which the rule applies. Each search engine has its own user-agent.
- Disallow: Tells the user-agent which pages or directories should not be crawled.
- Allow: Overrides a disallow directive, allowing specific pages or directories to be crawled.
- Sitemap: Provides the location of your XML sitemap.
Example of a Robots.txt File
User-agent: *
Disallow: /private/
Allow: /public/public-page.html
Sitemap: http://www.example.com/sitemap.xml
In this example:
- All user-agents are instructed not to crawl the
/private/directory. - The
/public/public-page.htmlis explicitly allowed to be crawled. - The location of the sitemap is provided.
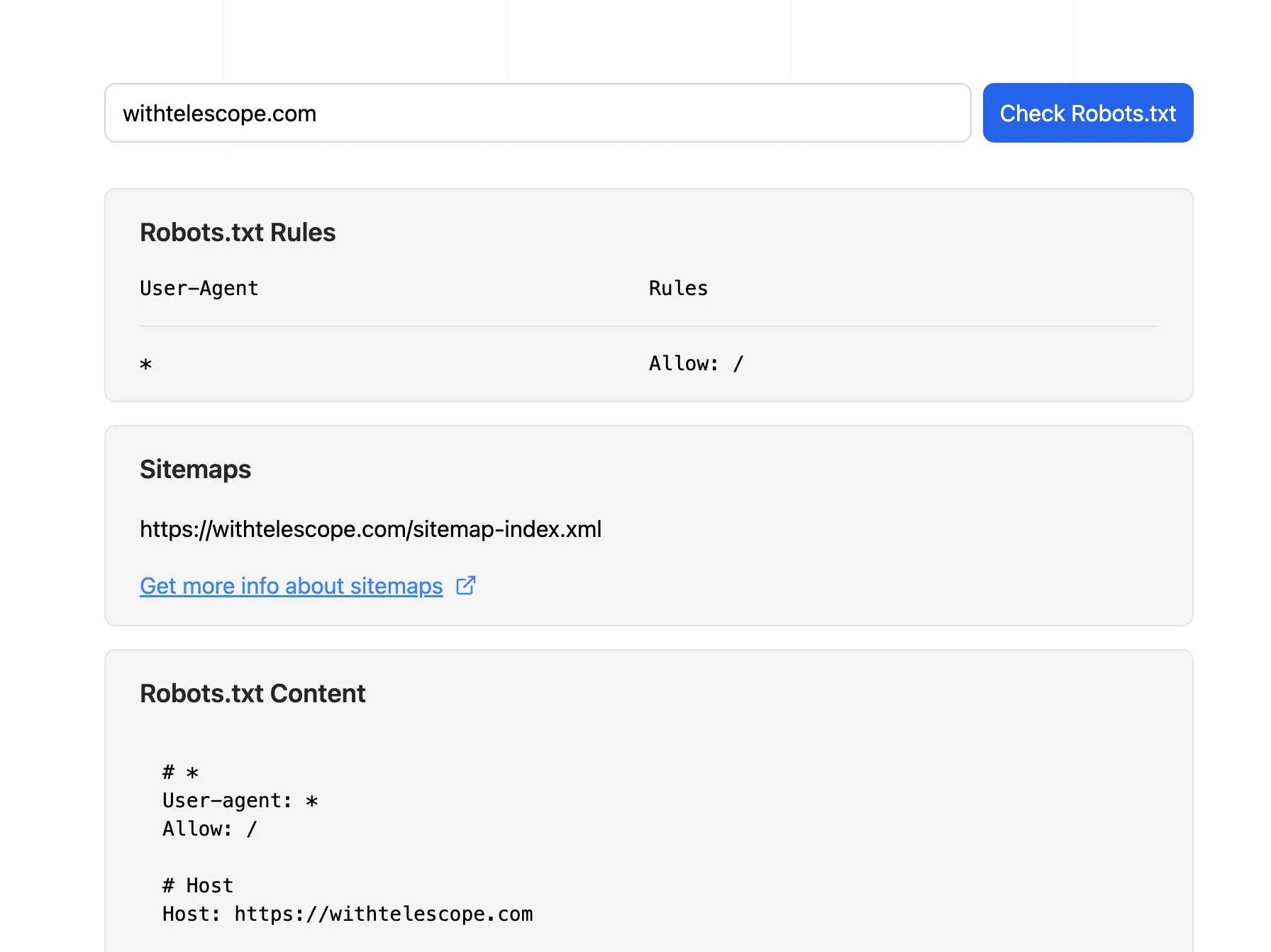
Testing Robots.txt
You can use our Robots.txt Tester to check if your robots.txt file is correctly configured and to preview how search engines will interpret it.
Why is Robots.txt Important for SEO?
1. Control Over Crawling
- Prevents overloading your server with requests from crawlers.
- Ensures that search engines do not index duplicate or low-value content.
2. Optimizing Crawl Budget
- Search engines have a limited crawl budget for each site. By directing crawlers to important pages, you make efficient use of this budget.
3. Preventing Indexing of Sensitive Information
- By disallowing certain directories or files, you can prevent sensitive or irrelevant information from appearing in search engine results.
How to Create a Robots.txt File
-
Create a Text File
- Use any text editor to create a file named
robots.txt.
- Use any text editor to create a file named
-
Add Directives
- Include the necessary user-agents and directives as per your requirements.
-
Upload to Root Directory
- Place the
robots.txtfile in the root directory of your website (e.g.,http://www.example.com/robots.txt).
- Place the
Best Practices for Robots.txt
1. Use Specific User-agents
- Target specific search engines if needed. For example:
User-agent: Googlebot
Disallow: /private/
2. Avoid Blocking Important Pages
- Ensure that important pages and resources (like CSS and JavaScript files) are not disallowed.
3. Test Your Robots.txt File
- Use tools like Google Search Console’s Robots.txt Tester to validate your file.
4. Regularly Update Your Robots.txt
- Keep your
robots.txtfile updated to reflect changes in your website structure and SEO strategy.
5. Use Wildcards and Dollar Sign
- Utilize wildcards (
*) and the dollar sign ($) for flexible and precise control.
User-agent: *
Disallow: /*.pdf$
6. Include Sitemap Location
- Always specify the location of your XML sitemap to help search engines find and index your pages more efficiently.
Common Mistakes to Avoid
1. Blocking All Content
- Avoid using
Disallow: /unless you want to block all content from being crawled.
2. Incorrect Syntax
- Ensure correct syntax to avoid misinterpretation by crawlers.
3. Case Sensitivity
- Remember that URLs are case-sensitive. Ensure that the paths in your
robots.txtmatch the actual paths on your website.
Conclusion
The robots.txt file is a powerful tool in your SEO arsenal. By understanding its components and following best practices, you can effectively manage how search engines interact with your website, optimize your crawl budget, and protect sensitive information. Regularly review and update your robots.txt file to align with your evolving SEO strategy and website structure.
For more in-depth guide to Robots.txt along with specifications, check out Google’s official documentation.